Infrastruktura AWS od środka.
Jedną z głównych prezentacji, które można było obejrzeć live na tegorocznej edycji re:Invent, było wystąpienie James’a Hamilton’a VP and Distinguished Engineer w Amazon Web Services. To już nie pierwsza tego typu prezentacja, gdzie James zdradza różne szczegóły techniczne jak wygląda AWS “od kuchni”. Ja ogładałem jego wystąpienie po raz pierwszy i zrobiło na mnie ogromne wrażenie (obejrzałem aż dwa razy). Jak dobrze wiemy, Amazon jak i inni nie zbyt chętnie dzielą się informacjami nt. rozwiązań jakie stosują. Nie raz uczestniczyłem w dyskusjach snujących nt. tego jak to czy inne rozwiązanie może być zaimplementowane. A zakładam, że część z was, tak jak ja jest osobami po części technicznymi, zatem takie informacje, zawsze budzą ciekawość.
Prezentacja James’a pokazuje kilka ciekawych faktów nt. infrastruktury AWS oraz z jakimi trudnościami czy wyzwaniami przychodzi im się mierzyć.
Rozmiar ma znaczenie

Tempo rozwoju infrastruktury AWS jest imponujące. Pierwsza rzecz o jakiej mówił James było to, że w 2015 roku każdego dnia, podkreślam każdego dnia AWS implementował tyle serwerów, że ich sumaryczna moc obliczeniowa równa była tej, która była potrzebna do utrzymania całej firmy 10 lat wcześniej. Firmy klasy Enterprise wartej wtedy $8,46B.
Wyobraźmy sobie, że każdego dnia, jest gotowych, zmontowanych, dostarczonych, potem zainstalowanych w szafach, prąd, sieć, całe okablowanie, itp, itd. tyle serwerów. I tak dzień w dzień!

Idąc dalej popatrzmy na rozmiar infrastruktury AWS. Dla przypomnienia, AWS dzieli swoje zasoby na Regiony, których jest obecnie 14, a kolejne 4 dojdą w najbliższym czasie. W ramach każdego Regionu są dwie bądź więcej Availability Zone, czyli niezależne od siebie lokalizacje. James powiedział również, że od teraz każdy kolejny Region będzie posiadał minimum trzy AZ.
Każda Availability Zone ma jedną bądź więcej serwerowni, a zdarzają się takie które mają ich aż osiem. W każdym z takich Data Center działa od 50 do 80 tysięcy fizycznych serwerów. I choć możliwe jest budować większych to jednak AWS przyjął,że taki rozmiar najlepiej się sprawdza. To pokazuje ile mocy obliczniowej dostarczane jest w ramach pojedyńczej AZ. James podkreslił, że niektóre Availability Zone, posiadają ponad 300 tysięcy serwerów. Mało? 🙂
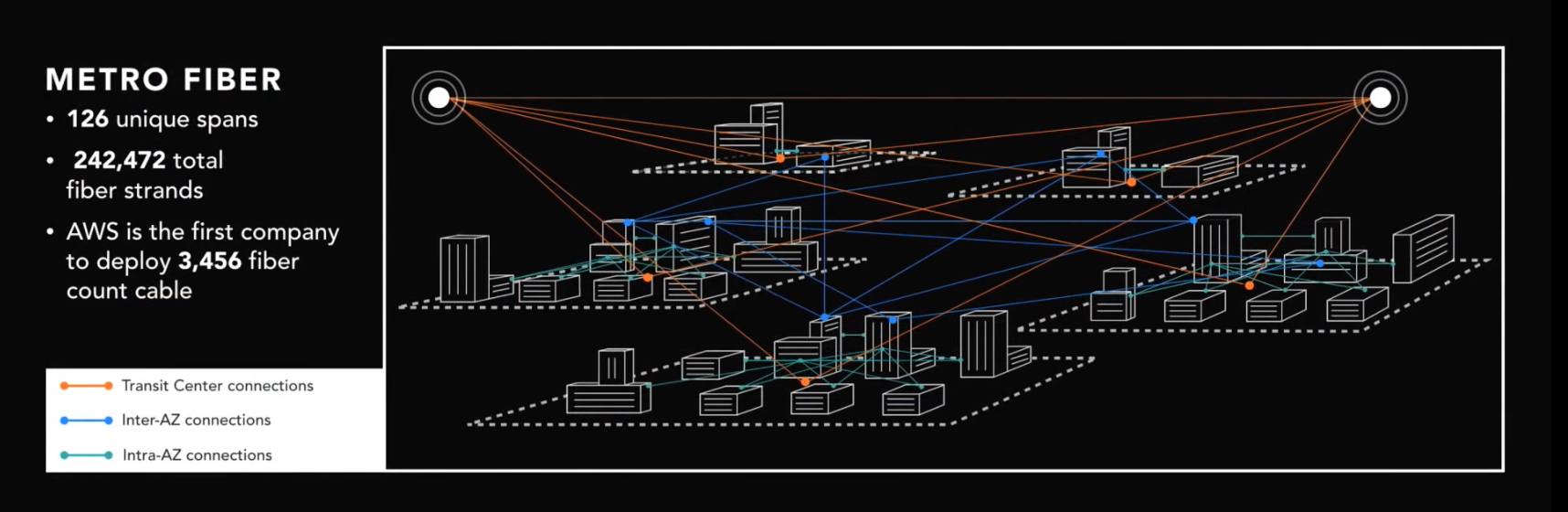
Przyglądając się przykładowemu regionowi, jak widać na schemacie, połączeń jest naprawdę sporo. Każda Availability Zone połączona jest z każdą redundantnie. To samo tyczy się każdego Data Center w ramach AZ. Wszystkie AZ przyłączone są do dwóch tzw. Transit Center czyli lokalizacji zapewniających komunikację z pozostałymi regionami. Również inne usługi jak np. AWS Direct Connet, czyli usługa dedykowanego połącznie do AWS również realizowana poprzez te dwa punkty. Liczby połączeń są naprawdę imponujące.
AWS Global Network
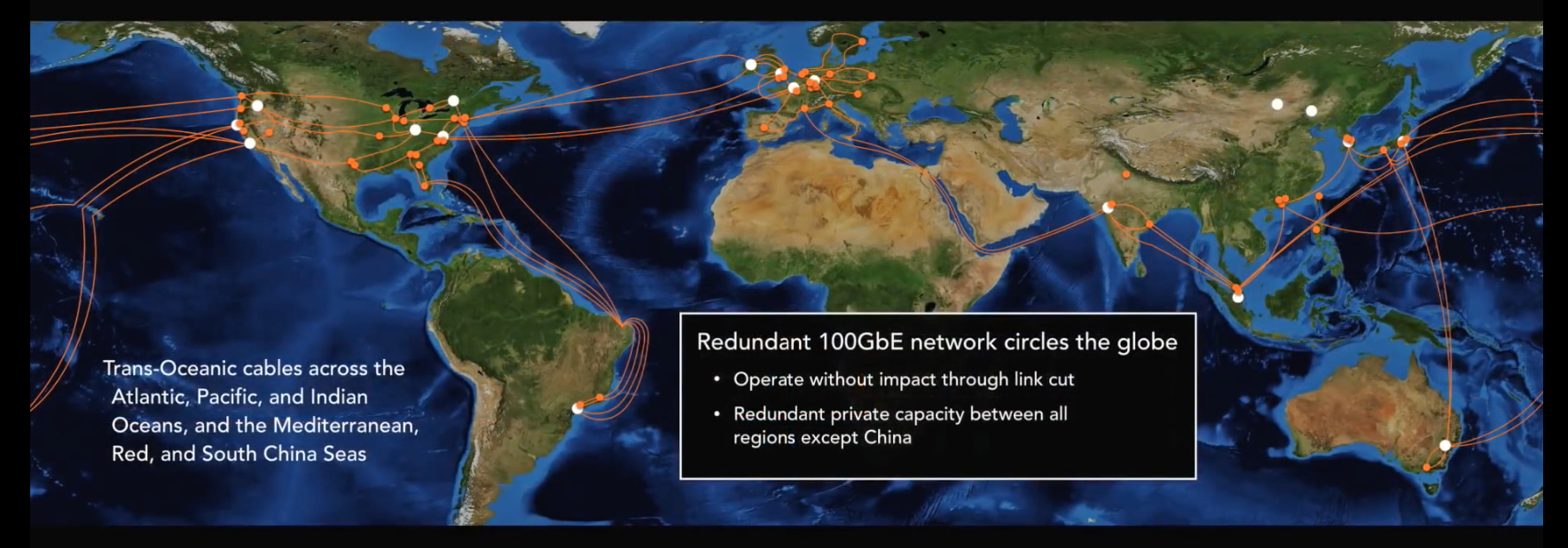
Amazon Global Network, czyli globalna sięc zapewniająca komunikację pomiędzy wszystkimi lokalizacjami. Jest to w pełni redundantna, należąca w całości i zarządzana wyłącznie przez AWS. Każde połączenie, każdy link jest 100GbE. Zbudowanie takiej sieci z pewnościa nie jest proste i np. jeden z ostatnich projektów to połączenie na dystansie 14,000km spinające Stany z Autralią.

Wyobraźmy sobie zbudowanie połączenia, którego część znajduje się 6000m ponizej poziomu morza. W dodatku najlepiej aby przez 20 lat nie wymagało konserwacji. Oraz taki “drobiazg”, że co 60-80km potrzebne są repeatery sygnału, które…potrzebują prądu 😎
Hardware
AWS tworzy sobie sprzęt sam. Mają np. swoje Routery oraz dedykowany protoloc development team. Ich celem jest aby zachować jak najwyższą niezawodność, dlatego budowanie własnego sprzętu/oprogramowania pozwala zachować prostote i pełną kontrole. Natrafiając na jakichś problem są w stanie bardzo szybko go rozwiązać, gdyż sprzęt jest ich, software jest ich, zatem wiadomo, kogo należy zaangażować.
Wszyscy dobrze wiemy ile czasem zajmuje realizacja case’u supportowego u vendora. W wielu przypadkach support musi zreplikować środowisko i problem aby go rozwiązać. Kto będzie w stanie zreplikować środowisko takiej skali o której przed chwilą pisałem? 😀
W przełącznikach i routerach wykorzystywane są porty 25Gb oraz customowe ASIC Broadcom Tomahawk mogące “przemielić” 128 takich portów w trybie non-blocking.
Ale James powiedział również, że od tego roku zaczeli tworzyć i używać własny krzem, który wykorzystują między innymi w serwerach.

Macierze dyskowe, które budują, w ramach jednej szafy Rack są w stanie upchnąć ponad tysiąc dysków zapewniając sobie pojemność 11PB! Mowa tu cały czas o klasycznej szafie 42U!

Serwery, wyglądające niepozornie w połowie puste obudowy zapewniają lepszą efektywność w perspektywy zasilania i chłodzenia niż tradycyjne rozwiązania. Dzięki takiemu projektowaniu uzyskali 1% wzrost efektywności, co przy skali infrastruktury AWS daje spore oszczędności. To bardzo dokładnie pokazuje jak firmie zależy na tym aby minimalizować koszty. Bo dzięki temu oraz efektowi skali są w stanie przekładać potem te oszczędności na klientów (ostatnio po raz kolejny ogłoszone były obniżki cen niektórych usług w tym Computingu).
Ambitne plany

W 2017 roku AWS planuje wdrożyć ponad 1000 usprawnień i nowych funkcjonalności. Poza tym firma ma też ambitny plan aby cała infrastruktura była zasilana w 100% energią odnawialną. Już w tej chwili region Oregion jes w całości zasilany tą metodą. Jak James pokazał idzie im to dość dobrze, w kwietniu 2015 było to 25%, a do końca tego roku planują osiągnać poziom 45%, a do końca następnego 50%. Docelowym założeniem jest generowanie rocznie 2.6 miliona MWhr.